平衡搜索树
2-3树
之前已经学习过了符号表的一些实现,不过我们的目标是将增删查的效率降为 logN。
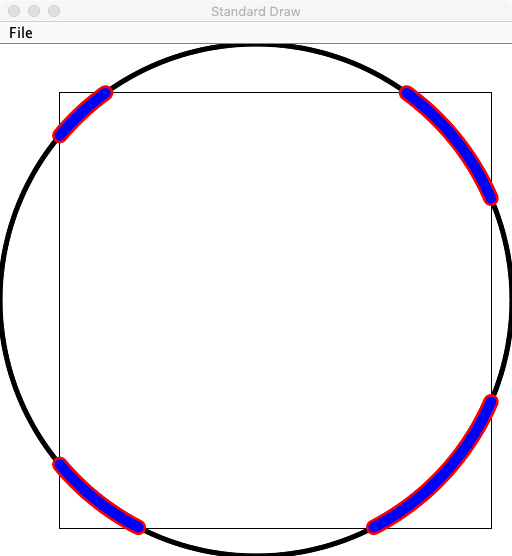
2-3树为了保证平衡性,规定每个节点可以存储1或2个值,存储1个值的节点分两个子节点,存储2个值得节点分三个子节点。且节点间的大小关系如下图所示。
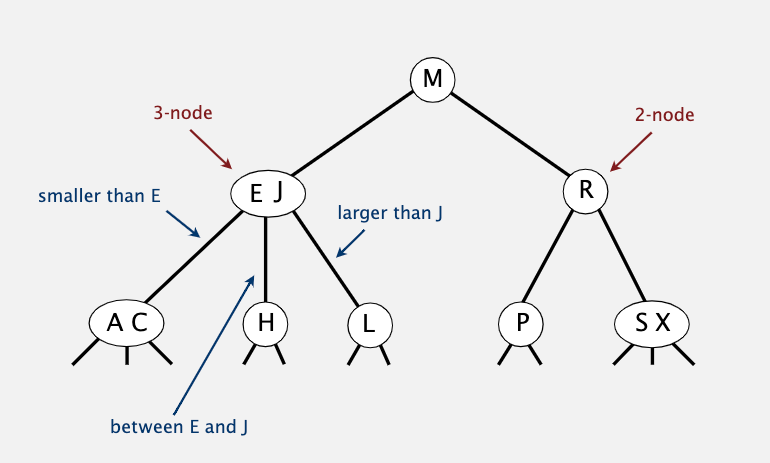
比较有意思的是它的插入过程。比如在上图的树中插入元素 Z,我们可以一直对比到最右下角的 S/X 节点,将 Z 插入该节点,这样它就变成了一个四分支节点。然后进行节点分裂,X 与父节点 R 组合在一起,S 和 Z 节点分离生成两个新节点。
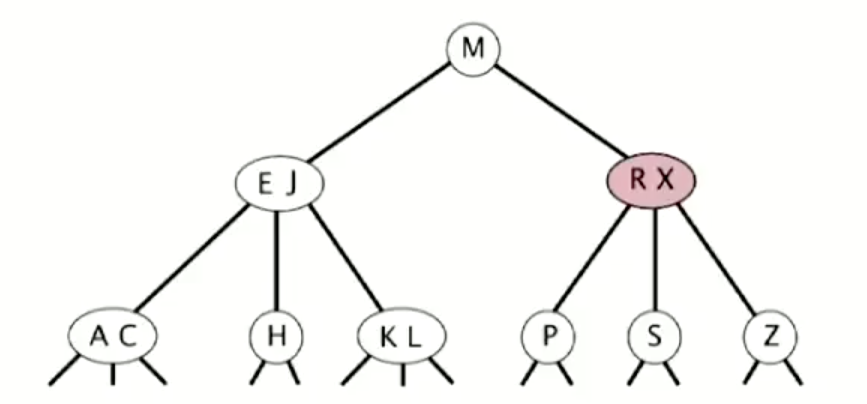
因为 2-3 树的平衡性很好,所以增删改查等操作仅仅需要 clgN 的时间复杂度。不过它太过复杂,需要考虑很多这种情况,所以并没有给出具体实现代码。我们有更好的解决方案。
红黑树
听到这几个字心情非常激动,大名鼎鼎的红黑树,无论是工作面试还是读研考试都会涉及到,而我一直畏惧没有接触。
在开讲前老爷子说了这么一番话:
On a personal note, I wrote a research paper on this topic in 1979 with Leo Givas and we thought we pretty well understood these data structures at that time and people around the world use them in implementing various different systems. But just a few years ago for this course I found a much simpler implementation of red-black trees and this is just the a case study showing that there are simple algorithms still out there waiting to be discovered and this is one of them that we’re going to talk about.
没想到屏幕后的教授就是红黑树的作者之一,并且在准备这门课时又想出了一种更简单的实现方法。能有幸听到红黑树作者讲红黑树,这是一件多么幸福的事啊。
其实红黑树就是对 2-3 树的一种更简单的实现。即含有两个键值的节点,将较小的节点分为较大节点的左子树,两者连接部分用红色标记。
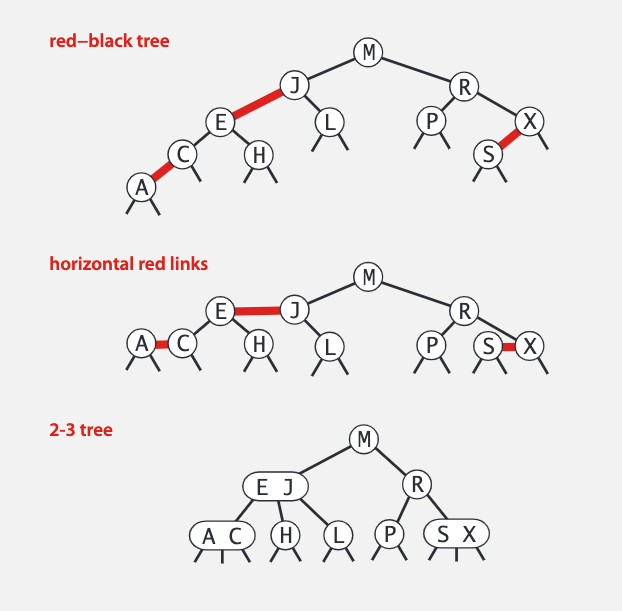
红黑树的 get()、floor() 等方法的实现跟普通的 BST 一样,只不过因为红黑树具有更好的平衡性,实际的操作速度会更快,在这里不进行详细的实现。
下面是红黑树的私有成员,主要多了标记红黑的部分。
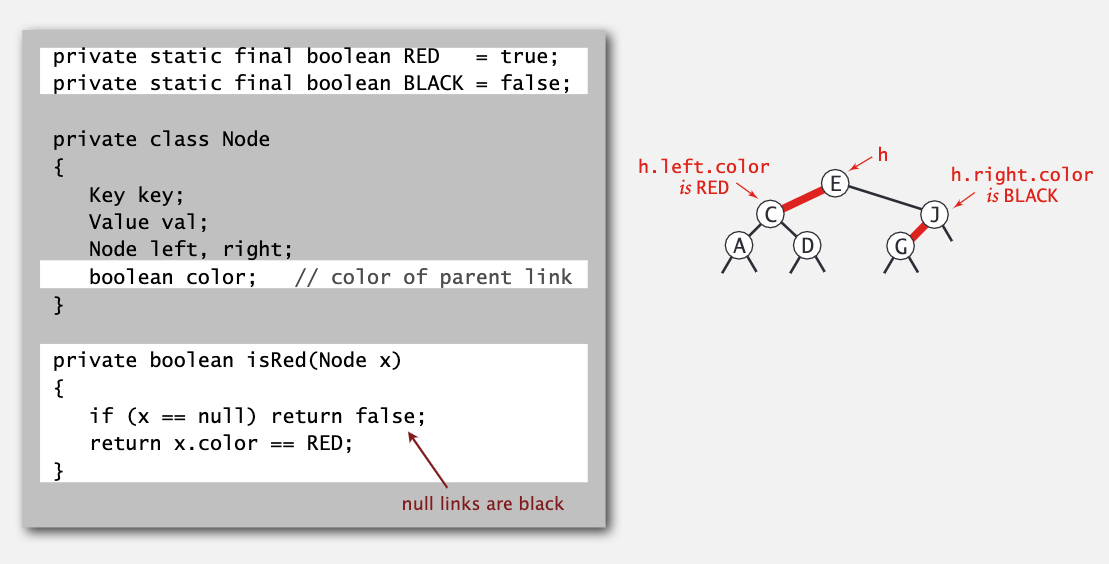
我们还需要实现一些私有类,便于插入删除等操作的实现。
1 | private Node rotateLeft(Node h) { |
有的时候红黑树会产生错误,即红色端链接在父节点的右分支上。上面的操作可以将子节点移动到左分支上。
1 | private Node rotateRight(Node h) { |
在插入时,有的节点可能会产生三个键值,我们需要让子节点分裂,中间节点合并到父节点中,改变节点的颜色就可以完成这个操作。
1 | private void flipColors(Node h) { |
下面就是插入元素的过程,用到了以上三种实现,就是先将元素插入到正确的位置中,再调整树的节点颜色。听老师讲的挺魔幻的,有空再好好总结一下。
1 | private Node put(Node h, Key key, Value val) { |
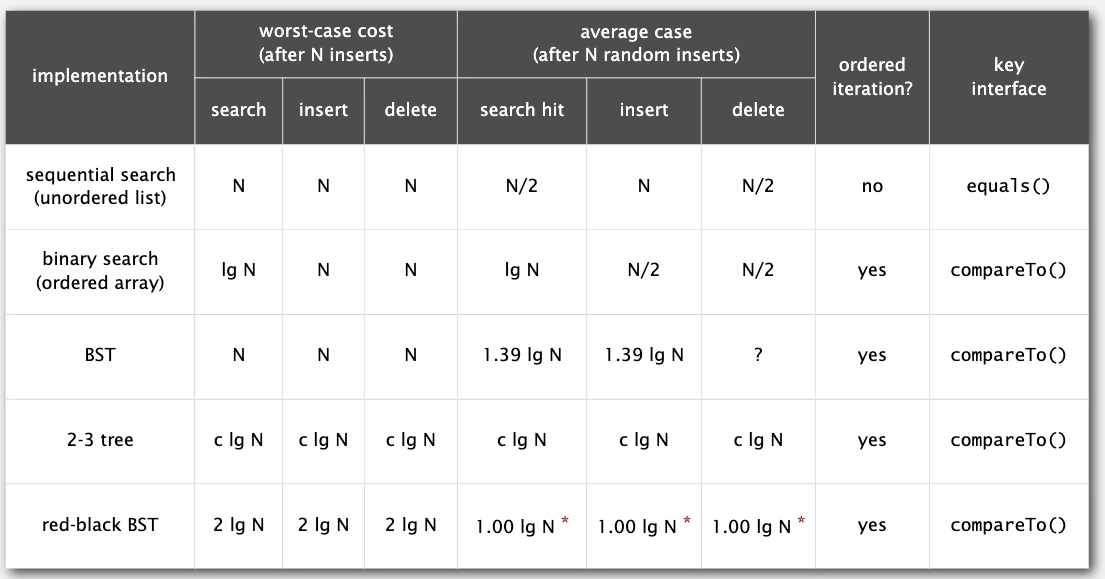
可以证明,红黑树的高度在最坏的情况下也不会超过 2lgN。
下面是红黑树的各操作的效率,很惊人了。
B 树
B 树是红黑树的一个实际应用。
通常我们使用外部存储来存储大量的数据,如果想计算出定位到第一页数据的时间,就需要一个切实可行的文件系统模型,B 树就可以帮我们实现这一点。
B 树的每个节点可以存储很多个键值。假设每个节点最多有 M-1 个键值,可以泛化出2-3个字树,则它只需满足以下几点:
- 根节点至少有两个键值
- 其他节点至少有 M/2 个键值
- 外部节点包含 key 值
- 内部结点包含 key 值得拷贝,以便指引查找
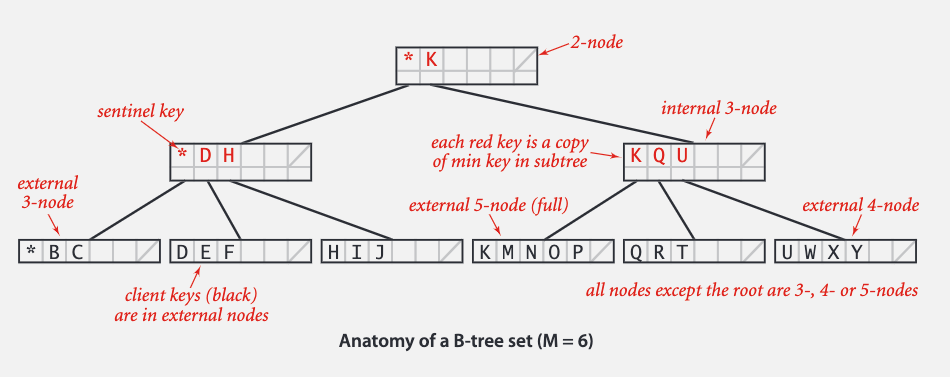
查找即依据索引一直查找到叶节点,插入也插入到叶节点需要时进行分裂。
每页 M 个键的 B 树中搜索或者插入 N 个键需要的时间在 $ \log {M-1} N $ 和 $ \log {M/2} N $ 之间。即使是万亿级别的巨型文件,我们也可以在5-6次搜索中找到任何文件。
平衡树的应用非常广泛,比如以下是红黑树的部分应用:
- Java: java.util.TreeMap, java.util.TreeSet
- C++ STL: map, multimap, multiset
- Linux Kernel: completely fair scheduler, linux/rbtree.h
- Emacs: conservative stack scanning
B 树和它的变形被广泛用于文件系统和数据库:
- Windows: NTFS
- Mac: HFS, HFS+
- Linux: ReiserFS, XFS, Ext3FS, JFS
- Databases: ORACLE, DB2, INGERS, SQL, PostgreSQL
最后老爷子讲到影视剧里也在谈论红黑树的梗,透着屏幕,你也能看得出他的骄傲和兴奋。
“A red black tree tracks every simple path from a node to a descendant leaf with the same number of black nodes.”
BST 的图形应用
一维空间搜索
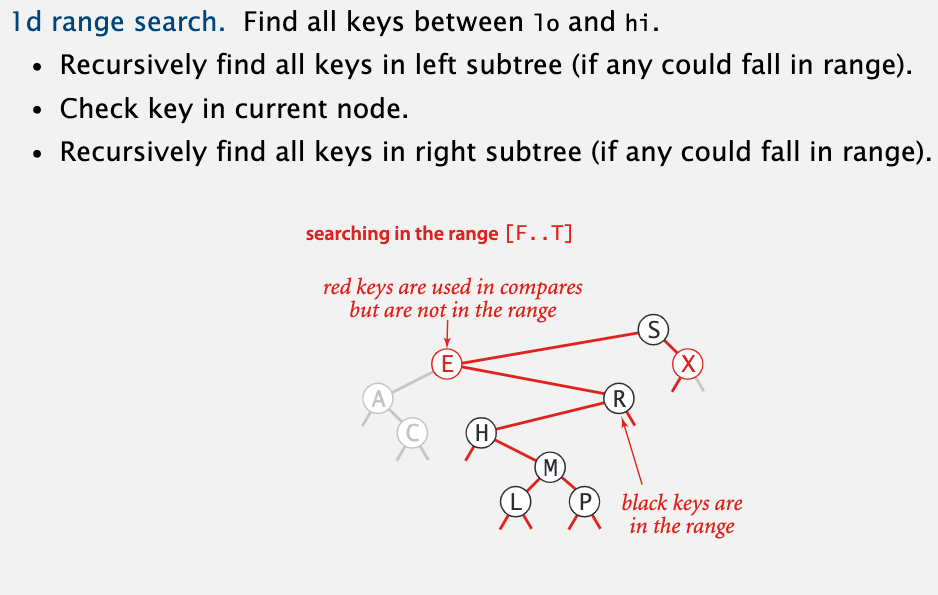
它主要需要实现两个操作:
- 区间搜索: 寻找 k1 和 k2 之间的所有键
- 区间计数:统计 k1 和 k2 之间键的个数
这个结构通常被用于数据库的查找中。
一般用有序或者无序的数组存部分操作都会达到 N 复杂度,而显然使用普通的 BST 可以确保每个操作都是对数复杂度。就比如说下面这个区间统计的方法:
1 | public int size(Key lo, Key hi) { |
下面是区间搜索的思路:
线段求交
线段相交即给出一组水平竖直的线段,求他们相交的部分。
最简单的思想是遍历每一个线段,并将它与其他线段比较,判断是否相交。不过这太慢了,会达到平方级别的复杂度,所以实际情况中根本无法使用。
我们使用扫描线算法和 BST 结合解决这个问题。假设竖直的扫描线从左到右扫描,遇到点就把它加到 BST 中,并记录 y 坐标,再次遇到这个 y 坐标的点就证明该条线段已经扫描成功,就把它移除 BST。
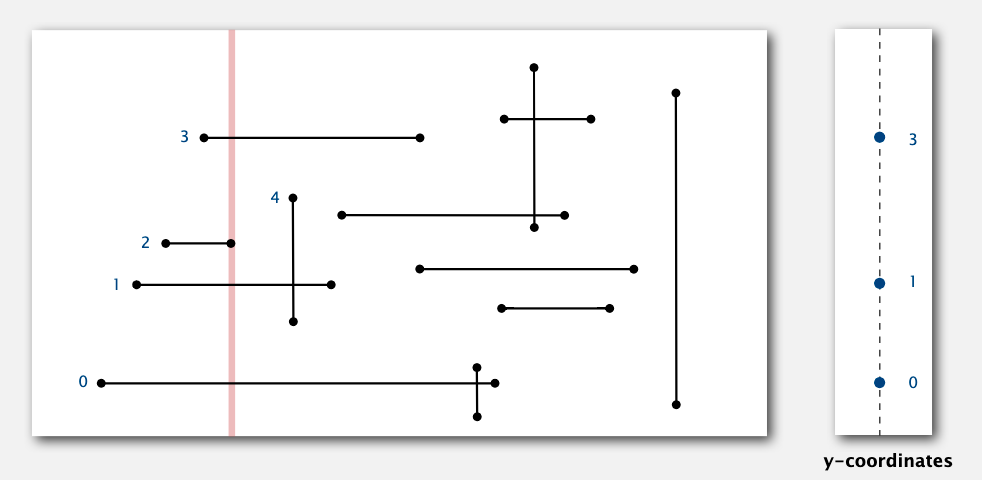
如果遇到竖直的线,就使用一维空间搜索看两个端点之间有没有水平直线的点,如果有,则证明他们相交。
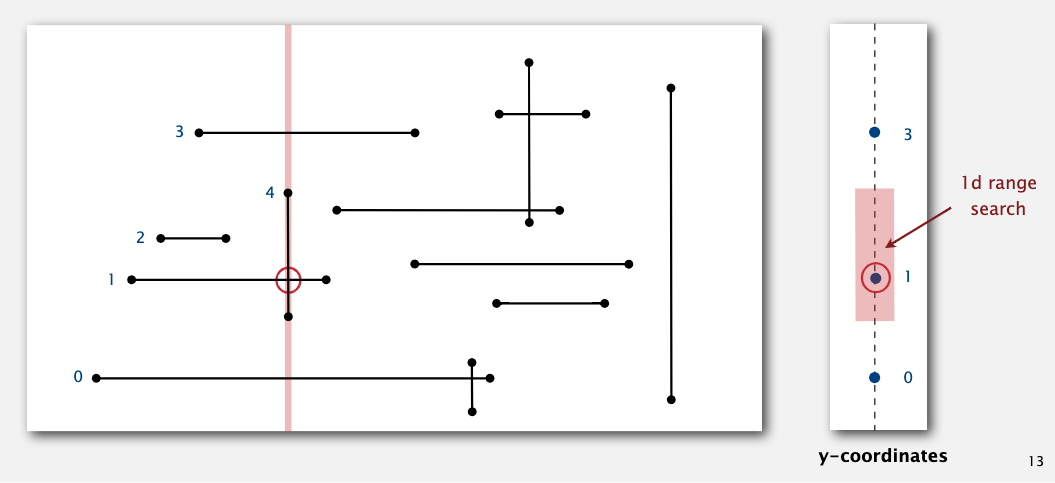
这个算法的复杂度就降到了 NlogN。
K 维树
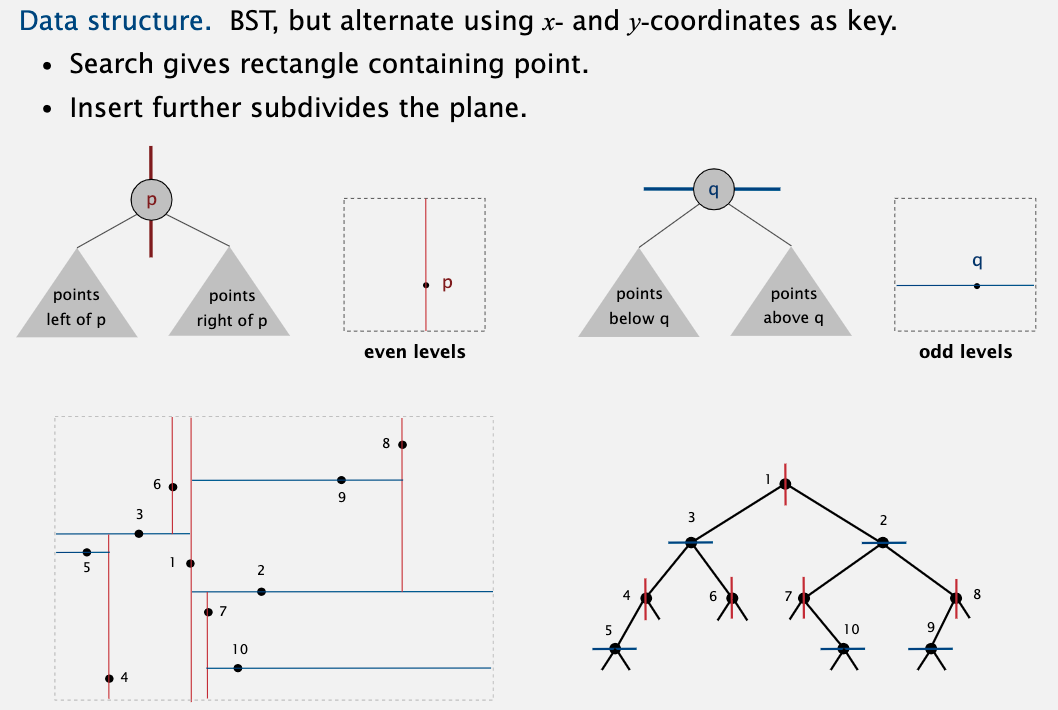
其中一个应用是统计二维平面中的点。通常情况下,二维平面中的点分布不均匀,所以采用递归分割的方式分割平面。
下面这张图清楚地表明了该 2d 树的数据结构,它的搜索效率一般只需 R + logN,最差为 R + √N。
还有一个应用是寻找与某个点距离最近的点。其实道理也很类似,就是将平面分区域搜索。
还有集群模拟、N 体问题等都有提到,不得不说这门课与前沿科技的结合还是非常密切的。
区间搜索树和矩形相交
这两点其实和线段相交类似,区间搜索树即每个节点的键值变为区间,实际上还是用 BST 做存储;矩形相交也用的扫描线,遇到竖直的矩形时用区间搜索看两端点之间是否含有子区间,如果有,则相交。
这部分没有特别细致的看,大概有个印象就是 BST 的应用的时间复杂度差不多都是对数级别。
编程作业:Kd 树
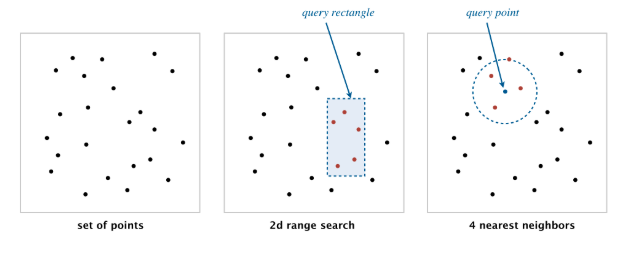
本周的作业就是实现 API,二维空间内给定一些点,可以判断点是否在给定区域内或者离一个点最近的点是哪个,有点类似 KNN 的算法。
第一种方法是用红黑树实现的,其实就是调用已有的数据结构实现 API,两个算法都用的暴力方法,感觉是想让学生熟悉一下整个 API,或是为了对之后高效的实现进行对比。
1 | public class PointSET { |
第二个是使用 2d 树实现,这个才是重点和难点。specification 中的描述少得可怜,就是大概说了说要实现的效果,实现方法什么的基本没提,后来在 checklist 中找到了一些思路。
一开始先实现 isEmpty() 和 size() 方法,因为它们很简单;然后实现 insert(),可以先不考虑 RectHV;再实现 contains() 后就可以写个 test 看 insert() 对不对;最后实现完 insert() 后完成 range() 和 nearest()。
1 | public class KdTree { |
其实最后总结起来几句话就完了,coding 的过程中真的问题百出。2d 树的建立就有很多问题,比如不知道怎样区别树的比较方向、RectHV 有什么用等;到 range() 和 nearest() 方法时也比较麻烦,比较那部分一点疏忽就跑不出来结果。
不过做了这么多次 programming assignment 也熟悉了,不停改不停翻 specification 和 checklist 总会写出来的,实在不行就看别人写的博客。