
优先队列和符号表
优先队列在入队时与传统队列相同,而出队时可以指定规则,比如最大元素/最小元素出队等,下面是一个简单的 API:

二叉堆
二叉堆是堆有序的完全二叉树,键值存储在节点上,且父元素的键值比子元素的键值大。我们可以推测出最大的键值在根节点上,也就是 a[1](不使用数组的第一个位置)。
二叉堆实际存储在数组中,如果一个节点的索引是 k,那么它的父节点的索引是 k / 2, 子节点的索引是 2k 和 2k + 1。
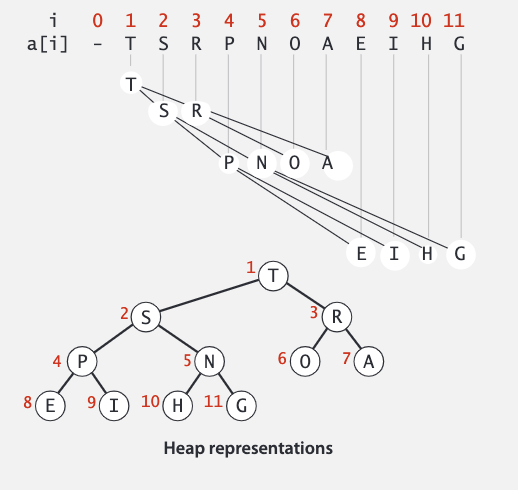
如果某一节点的堆有序被破坏了(子节点比父节点大),我们可以使用下面的算法恢复:
1 | private void swim(int k) { |
因此实现添加操作时将待添加的元素插入到树的下一个子节点,然后通过 swim() 方法将其移动到正确的位置上,这个操作最多需要 1 + lgN 次比较。
1 | public void insert(Key x) { |
还有一种情况是父节点比两个子节点小,使用“下沉”的思想可以很好解决它:
1 | private void sink(int k) { |
sink() 方法利于实现删除操作,将首节点和尾节点互换位置,删除尾节点,再将首节点移动到合适的位置。这个操作最多需要 2lgN 次比较。
1 | public Key delMax() { |
下面是完整的二叉堆的实现,这种实现的插入和删除操作都是 logN 的时间复杂度。
1 | public class MaxPQ<Key extends Comparable<Key>> { |
堆排序
堆排序分为两个阶段,第一个阶段是将数组安排到一个堆中,最好的方法是使用“下沉”操作,N 个元素只需要少于 2N 次比较和少于 N 次交换。
第二个阶段是通过二叉堆的删除方法,每次将二叉堆中最大的元素筛选出来,筛选出来的数组则是有序的。
1 | public class Heap { |
堆排序最多需要 2NlgN 次比较和交换操作,而且它是一个原地算法。
不过堆排序并不像想象中那么好,比如 Java 的 sort() 方法中就没有使用堆排序,它主要由以下三个缺点:
- 内循环太长
- 没能很好地利用缓存
- 不稳定
关于第二点,我一开始也不是很理解,后来 Google 除了答案。堆排序的过程中经常访问相距很远的元素,不利于缓存发挥作用;而快排等算法只会访问到局部的数据,因此缓存能更大概率命中,即局部性更强。
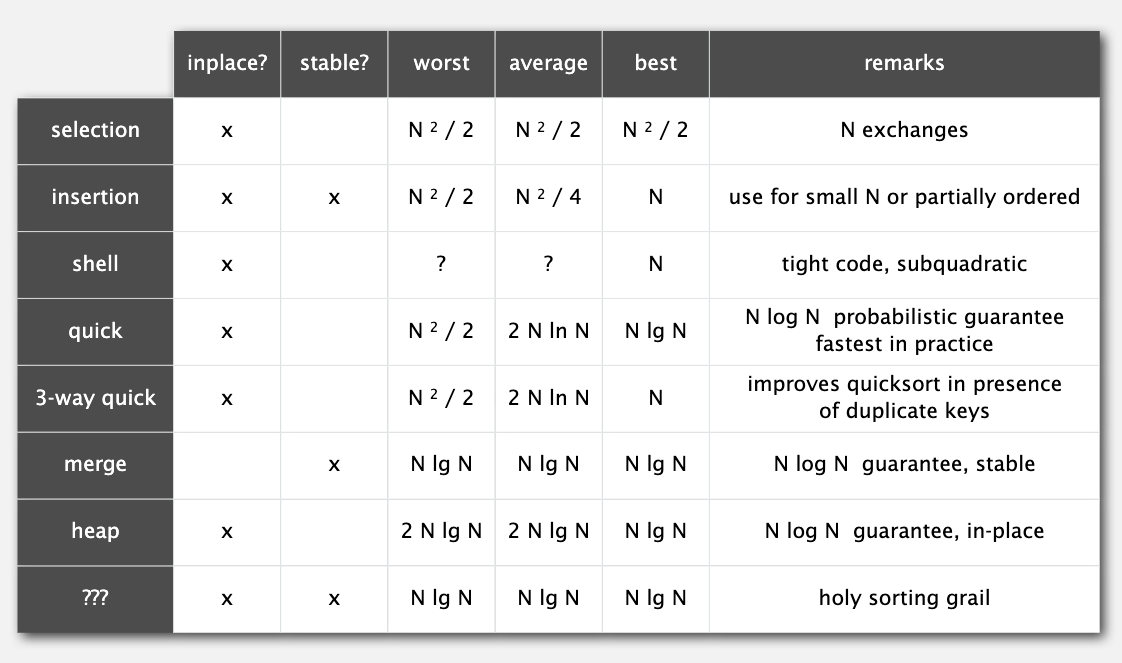
下面是截至目前所学排序算法的总结:
符号表
下面是符号表的 API。

位查找
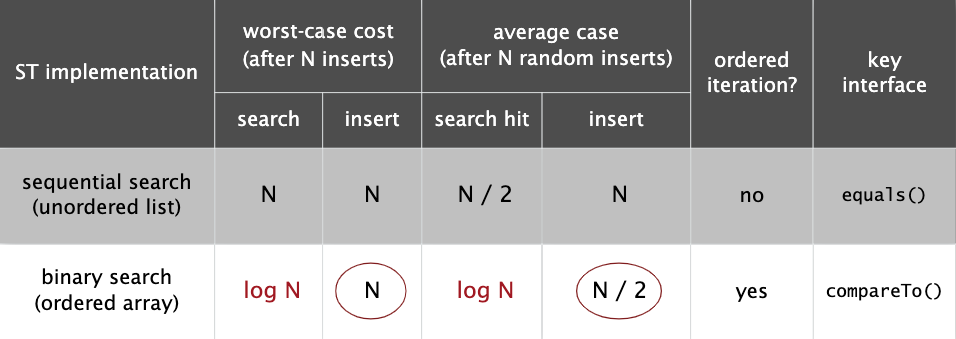
实现符号表最简单的方法是使用链表,不过插入和查找操作都需要遍历整个链表,复杂度为 N。
因此我们可以使用两个数组实现,一个存储 key,一个存储 value,且存储是有序的。
1 | public Value get(Key key) { |
不过插入要移动数组元素。
二分查找树
二分查找树实际上是一颗二叉树,节点上有值。父节点比所有左子节点上的元素大,比所有右子节点上的元素小。
1 | public class BST<Key extends Comparable<Key>, Value> { |
BST 的效率跟插入元素的顺序有关,最差的情况是所有节点都在其父节点的右子树上。
下面是二叉查找树各方法的效率:
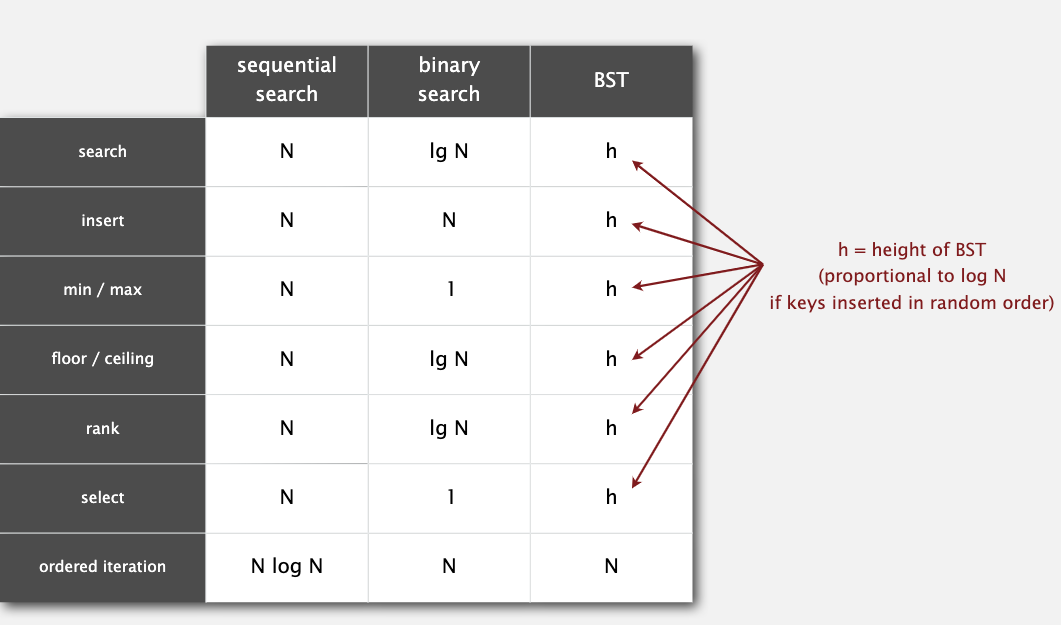
下面是二叉查找树与之前数据结构的对比:
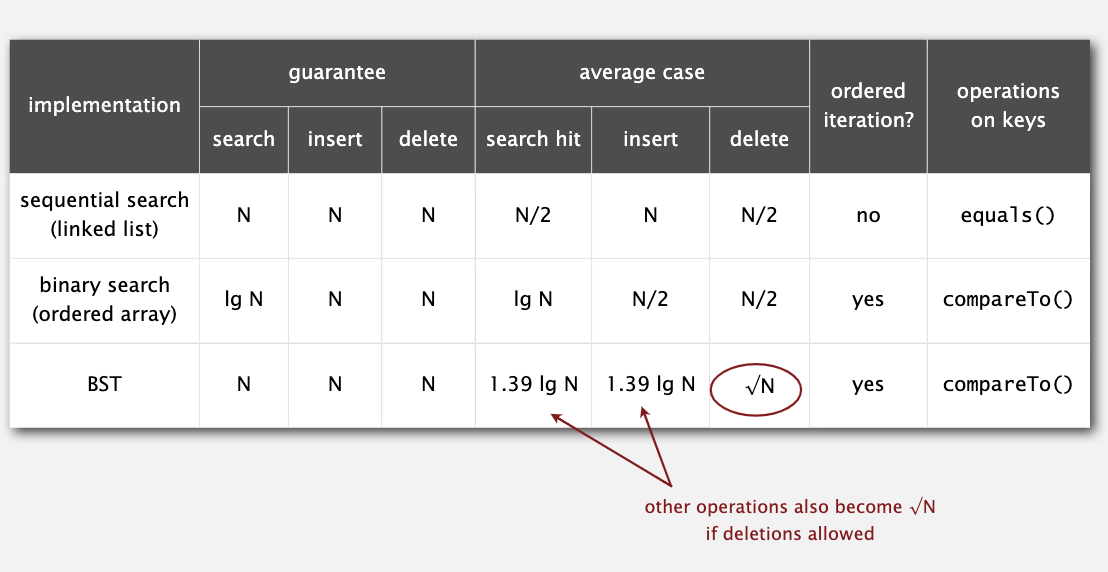
它的删除算法不算好,树的形状很容易偏向一侧,至今都没有什么好的解决办法。
编程作业:8 Puzzle
本次的作业是写一个游戏 AI,游戏即将一个无序的矩阵通过空白格的交换达到有序,如下图所示:
1 | 1 3 1 3 1 2 3 1 2 3 1 2 3 |
讲真这次的作业做了好久好久,主要是不理解一开始给出的算法,只能硬着头皮边实现 API 边理解文档,最后调 bug 又调了两个小时,总之感觉是目前接触到最难得一次吧。
解决整个问题最核心的是 A* search 算法。每个矩阵都看作是一个搜索节点,一开始在 MinPQ 中插入所给的节点,然后删除最小的节点,并将最小节点的所有移动方法再插入到优先队列中,重复上述操作,直到队列中的最小节点有序。
所谓最小,即整个矩阵的复杂度最小,有 Hamming 和 Manhattan 两种优先度算法。两种方法都要经过测试,不过真正实现的时候要用 Manhattan 算法。
A* search 算法的操作可以想象成一棵博弈树,为了最终找到操作的过程,每个子节点还要存有父节点的引用。
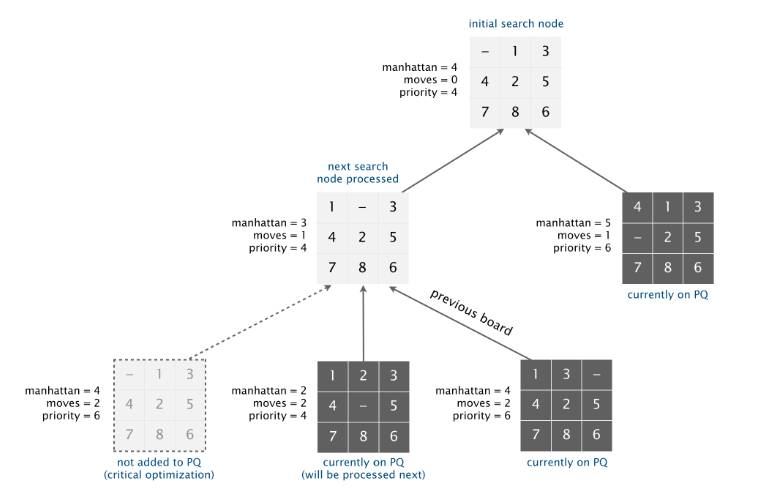
还要考虑的一种情况是,所给的矩阵根本无法调整为有序。这里的算法一直都不是很懂,一开始将原始节点的两个位置互换创建伴随节点啊,然后进行和原始节点相同的操作,如果原始节点无解的话,那么伴随节点一定有解。有兴趣的可以看一下这篇论文,给出了算法的证明。
大致梳理了一下思路后,就没有什么难懂的地方了。
Board 类主要就是记录输入数据,并实现比较规则以及一些生成方法供后续使用。
1 | public class Board { |
Solver 类包含一个内部类,即搜索节点,它主要包括 Board 和移动次数等信息。构造函数实现了 A* search 算法,其余方法只是为了输出结果。
1 | public class Solver { |
讲义中提到的几点优化一定要完成,效率会提高不少。还有一定要注意 Board 的输出格式,我就是少了个空格曾经一度得零分十几分。
测试数据并不是很难,我本地 puzzle50 没跑出来不过提交似乎没测试这么大的数据。可见这个 Ai 的算法还是有局限性的,对于 4*4 以上的复杂情况很难算出来。
最后部分数据超内存得了 95 分,下面上图感受一下曾经崩溃的心理。
幸亏不罚时。